10.Python 網路爬蟲原始碼
健康有機水果蔬菜線上商城網站模板, HTML5購物體驗商城宣傳網站模板, 時尚鞋服配飾泳裝線上商城網站模板, 時尚單品折扣商城網站模板, HTML5歐美時尚服飾網站模板, 時尚女士墨鏡品牌宣傳網站模板, 機械維修裝置電子商城網站模板, 時尚服飾單品銷售服務網站模板, 時尚服裝購物線上商城網站模板, 時尚女裝線上預定購買網站模板, 時尚服飾單品折扣網站模板, 線上服裝購物商城網站模板, 鞋服線上購物服務網站模板, 運動鞋品牌購物商城網站模板, 鞋服配飾電子產品商城模板, 時尚運動鞋類商城網站模板, 太陽眼鏡線上購物商城模板, 服裝摺扣商城網站模板, 線上購物服裝商城網站模板, 網上購物商城HTML5模板, 鞋類產品HTML5網站模板, HTML5時尚服飾單品網站模板, 線上服裝商城網站模板, 運動鞋折扣商城網站模板, 電子商務服裝商城網站模板, 嬰兒用品服裝網站模板, 電子商務服裝商城網站模板, 極簡電子商務網站HTML5模板, 多用途電子商務HTML5模板, 小清新果汁飲品商城網站模板, 布娃娃線上商城網站模板, 紅黑設計聖誕節禮物商城模板, 聖誕節主題商城網站HTML5模板, 跑步鞋新款上市商城網站模板, 戶外行李雙肩包商城網站模板, 雙11雙12商城電子商務網站模板, 黃色樣式商城模板網站下載, 現代時尚服裝商城網站模板, 響應式小型服飾商城網站模板, 白色極簡商城HTML網站模板, 簡潔的響應式電子數碼商城模板, 品牌運動鞋搶購平臺網站模板, 響應式服裝電子商城網站模板, 綜合類網店商城網站HTML5模板, 簡約乾淨的家居商城網站模板, 時尚鞋子商城的Bootstrap模板, 酒莊葡萄酒網上商城網站模板, 黑白風格模特服裝商城模板, 響應式服裝商城網站HTML模板, 精品手錶配飾商城網站模板, 電子商城後臺管理系統模板, 新鮮水果購物商城HTML5模板, 時尚品牌服裝銷售商城模板, 綠色新鮮水果商城網站模板, 女性服裝購物商城網站模板, 家用電器商城響應式HTML5模板, 智慧數碼產品銷售商城模板, 商城訂單銷售統計管理模板, 潮流時尚服裝商城HTML5模板, 手工商品電子商務網站模板, 服裝配飾銷售商城HTML5模板, 衣服服裝商城HTML5模板, 有機蔬菜水果食品商城網站模板, 生活傢俱電子商務網站模板, 電子商務圖文部落格網站模板, 時尚女裝銷售商城網站模板, 時尚家居商城HTML5模板, 數碼電子產品銷售HTML5模板, 寬屏大氣電商網站HTML5模板, 國外服裝商城官網網站模板, 有機食品零售商城HTML5模板, 服裝穿戴商城網站模板, 有機食品購物商城網站模板, 二手舊手機銷售網站模板, 電子數碼產品商城網站模板, 傢俱店舖商城HTML5模板, 太陽鏡網上商城頁面模板, 綜合類購物商城網站模板, 綜合購物電子商務網站模板, 衝擊鉆電鉆商城網站模板, 自行車網上商城HTML5模板, 多用途購物商城網站模板, 海外購物商城HTML模板, 網上禮品商店HTML5模板, 無人機購買商店HTML5模板, 醫療物資器械商城模板, 多肉盆栽植物商城模板, 數碼電子產品銷售電商模板, 戶外穿戴攝影商城模板, 男士服裝配飾商城網站模板, 數碼影音娛樂商城網站模板, 服裝網上商店網站模板下載, 外貿B2B商城首頁模板, 北歐風格傢俱商城網站模板, 生活電器商城企業網站模板, 手錶電子產品商城模板, 分類商店平臺網站模板, 扁平化女裝鞋包商城模板, 室內傢俱購物網站模板, 運動鞋電子商務網站模板, 電子商務平臺服裝商城模板, 寬屏揹包商城網站模板, 服裝電子商務網站模板, 寬屏運動鞋商城網站模板, 商家目錄綜合服務O2O模板, 摩托車配件銷售商城模板, 電子商務綜合商城網站模板, 電工裝置線上商城網站模板, 白色簡潔時尚家居商城模板, 大氣電子商務商城主題模板, 小清新電商傢俱商城模板, 手工藝術品線上商店模板, 網上傢俱商城HTML5網站模板, 黃色室內傢俱電商商城模板, 運動鞋線上商城HTML5模板, 實木傢俱電子商務網站模板, 服裝外貿電子商務網站模板, 時尚女性服裝商城網站模板, 智慧手錶線上商城網站模板, 響應式藍色商城HTML5模板, 服裝商城整站HTML5模板, 葡萄酒網上商城網站模板, 耐克品牌鞋商城網站模板, 高階精品家居商城網站模板, 左欄導航服裝購物商城模板, 服裝休閒鞋商城網站模板, 寬屏大氣時裝網站模板, 服裝電子商務網站模板, 黑色手錶線上商城網站模板, 女性內衣內褲商城網站模板, 奢侈品手錶商城網站模板, 手機數碼商城前端框架模板, 鑽石珠寶線上商城網站模板, 毛絨玩具網上商城HTML5模板, 潮牌服裝商城響應式模板, PC電腦端服裝購物網站模板, 手機電腦音箱商城網站模板, IT電子產品商城網站模板, 簡潔白色手機銷售商城模板, 高階時尚時裝網店商城模板, 網上配眼鏡商城網站模板, 響應式耳機商城HTML5模板, 保潔家政服務公司網站模板, 綠植盆景商城HTML模板, 手機電腦商城HTML5模板, 手工編織揹包創意網站模板, HTML5滿屏電子商務創意模板, 眼鏡網上商城HTML5模板, 英語書本商城網站模板, 網上商城電子商務網站模板, 百貨商城全站HTML模板, 精美響應式電子商務模板, 黑色素雅工藝品網站模板, 運動服裝購物網站模板, 綠色傢俱商城html5模板, 數碼產品銷售商城網站模板, 老爺車二手車商城網站模板, 服裝商城綠色網站模板, 果蔬網上商城HTML5模板, 電子產品商城模板Complex, 電子購物商城網站模板, 全屏鞋子商城單頁模板下載, 藍色大圖服裝商城網頁模板, Bootstrap3通用商城模板, 鞋服線上商城網站模板, 兒童用品電商HTML模板, 適合大型電子商務html5模板, 綠色水果網上商城模板下載, 有機水果蔬菜商城模板, 藍色大氣電商網站模板, 可愛的兒童用品商城模板, 響應式甜品網上商城模板, 化妝品電子商務網站模板, HTML5扁平化電商網站模板, 多功能電子商務網頁模板, 相容手機html5電商模板, HTML5傢俱商城響應式模板, 服裝電子商務公司網站模板, 手機數碼電子購物商城模板, 一元云購商城網站模板下載, 商場網上購物CSS3整站模板, 前端開發公司HTML5模板, 服裝鞋帽購物商城網站模板, 時裝線上購物商城網站模板, 時尚購物網上商城HTML5模板, 服裝電商網上商城HTML5模板, 電子產品百貨商城網站模板, 摩托車汽配銷售網站模板, 車展汽車展示html模板, 女性高跟鞋商城網站模板, 個性潮流服裝商城模板, 網上運動商品銷售網站模板, html購物網站模板下載, 運動鞋商城網站模板, 女性奢侈品商城網站模板, 游泳泳衣商城網站模板, 手機購買商城模板下載, 手機銷售電子商務模板, 服裝商城html網站模板, 手錶b2c商城網站模板, 新鮮水果商城CSS模板, 足球運動鞋商城網站模板, 服裝品牌商城模板, 運動鞋網上銷售HTML模板, 圖書網上商城模板下載, 大氣購物商城模板免費下載, 高階奢侈品網上商城模板, 購物shopping商城網站模板, b2c商城購物網站模板, 手錶商城CSS網站模板, 服裝銷售商城HTML模板, 街拍服飾商城網站模板, 網上眼鏡商城網頁模板, 女性服裝商城網站模板, 登山外套B2C商城網站模板, 棕色鞋子商城網站模板, 時尚服裝電子商務商城網站模板, HTML5運動裝線上商城網站模板, Bootstrap4傢俱線上商城網站, 美容化妝品電子商務Bootstrap5, 傢俱電子商務Bootstrap5網站, 時尚女裝配飾電子商務網站, 汽車配件商店HTML5網站, 時尚服飾網上商城Bootstrap, 回應式圖書電子商務網站模板, 鬍子護理精油電子商城Bootstrap5模板, HTML5極簡主義傢俱電子商務網站模板, 時尚折扣服裝配飾Bootstrap5模板, HTML5保健品營養品商城網站模板, HTML5兒童玩具商城網站模板, 時尚手錶線上電子商務網站模板, 極簡風傢俱電子商務網站模板, HTML5家居傢俱電子商務網站模板, 摩托車機車電子商務HTML5模板, 簡約風傢俱線上商城網站模板, 時尚品牌服飾配飾電子商務網站模板, 小眾時尚單品線上電子商務網站模板, 響應式時尚單品線上商城網站模板, 時尚藤編傢俱電子商務網站模板, 時尚美體塑身衣電子商城網站模板, HTML5時尚傢俱椅子電子商務網站模板, 大學教育服務機構宣傳網站模板, 企業線上諮詢服務公司網站模板, 體育健身鍛鍊機構服務網站模板, IT解決方案服務公司宣傳網站模板, 體驗自行車騎行服務網站模板, 響應式網際網路公司網站模板, HTML5航空旅行航班預定網站模板, 網際網路業務服務公司HTML5模板, 高級汽車租賃服務公司網站模板, 企業解決方案服務網站模板, 新冠病毒知識宣傳網站模板, 域名託管服務公司宣傳網站模板, 家居專業規劃服務公司宣傳網站模板, 扁平風數字信息技術服務公司網站模板, 藍色風格數字搜索引擎優化網站模板, 創意營銷開發設計公司網站模板, 網際網路公司業務服務宣傳網站模板, 網頁遊戲平臺宣傳網站模板, 咖啡店宣傳服務網站模板, 遊艇租賃服務機構網站模板, 黑色星期五折扣商城網站模板, 珠寶配飾電子商城網站模板, 時尚鞋服配飾線上商城網站模板, HTML5時尚鞋服電子商城網站模板, SPA精油線上購物網站模板, 時尚鞋品線上商城網站模板, 響應式時尚鞋服折扣商城網站模板, HTML5線上服裝超市網站模板, 時尚服裝商城線上購物網站模板, 山地自行車電子商城網站模板, 婚禮珠寶飾品線上網站模板, 夏季時尚服裝配飾電子商城網站模板, 旅行酒店預定汽車出租服務網站模板, 響應式HTML5探索世界旅行網站模板, 美容護膚SPA行業網站模板, HTML5保護環境保護動物宣傳網站模板, 地板修補瓷磚供應商網站模板, IT技術解決服務商宣傳網站模板, HTML5公益救助服務網站模板, 網際網路資料SEO服務網站模板, 家居裝潢清潔維修服務公司網站模板, HTML5網頁設計服務公司網站模板, 數字營銷機構宣傳服務網站模板, 響應式法律諮詢服務網站模板, 紫色風格外匯交易服務網站模板, HTML5現代工業公司宣傳網站模板, 現代工程建築公司網站模板, 網上鮮花預定折扣商城網站模板, 網上電子書店商城網站模板, 時尚男女服飾線上折扣商城網站模板, HTML5奢侈品手錶店宣傳網站模板, 時尚手錶單品線上商城網站模板, 進口有機茶葉電子商務網站模板, 時尚女士內衣線上商城網站模板, 登山運動鞋品電子商務網站模板, 數碼產品裝置線上商城網站模板, 禮物選購線上商城網站模板, 歐美潮流服飾線上商超網站模板, 電腦手機電子配件電子商城網站模板, 兒童益智玩具商城網站模板, 線上書品選購商城網站模板, 新鮮水果蔬菜線上電商網站模板, 響應式禮品線上商城網站模板, 時尚冬裝線上購物商城網站模板, 應用程式線上商店宣傳網站模板, 響應式特色手錶線上購物商城模板, 現代傢俱設計工作室網站模板, 紅色風格IT解決方案業務服務網站模板, HTML5比利時旅行網站模板, 網際網路業務服務響應式網站模板, 網際網路業務服務響應式網站模板, HTML5游泳館宣傳網站模板, IT服務公司宣傳網站模板, 網路線上課程教育服務網站模板, IT解決方案定製服務網站模板, 響應式HTML5婚禮服務網站模板, IT解決方案服務公司網站模板, SEO數字營銷代理服務網站模板, 極簡風設計工作室宣傳網站模板, 響應式汽車維修保養服務網站模板, 響應式理財貸款服務公司網站模板, 桌椅辦公傢俱公司HTML5模板, IT業務服務公司網站模板, 數字解決方案增長機構網站模板, HTML5遠端教育服務機構網站模板, 時尚潮流服裝商城線上網站模板, 虛擬貨幣交易服務公司網站模板, HTML5遊艇租賃服務宣傳網站模板, 現代主題咖啡店宣傳網站模板, 工業製造行業HTML5網站模板, 響應式足球俱樂部宣傳網站模板, HTML5花卉線上交易網站模板, 老年護理服務機構網站模板, HTML5管理諮詢服務公司網站模板, 全球旅行網站HTML5模板, 新聞資訊分享網站模板, 自行車購買配件服務網站模板, HTML5心理諮詢服務公司網站模板, 響應式設計代理服務公司網站模板, 創意代理機構宣傳網站模板, 平面設計師個人求職簡歷網頁模板, 小眾創意工作室宣傳網頁模板, HTML5風能新能源公司網站模板, 創意視覺設計師個人簡歷網頁模板, 響應式營銷公司宣傳網站模板, 藍色醫療保健服務管理網站模板, 房地產建築服務公司宣傳網站模板, HTML5理療服務網站模板, HTML5醫療服務機構宣傳網站模板, HTML5創意代理機構服務網站模板, 企業數字營銷服務公司網站模板, 自由職業者個人簡歷網頁模板, 線上商務服務公司HTML5模板, 響應式企業諮詢管理服務網站模板, 電子商務管理系統服務公司網站模板, 藍色風格財產保險服務公司網站模板, 雲端計算域名託管服務公司網站模板, 自行車服務公司宣傳網站模板, HTML5網頁設計服務公司網站模板, 現代設計代理服務公司網站模板, 響應式HTML5電子書網站模板, 響應式營銷公司宣傳網站模板, 家政保潔服務公司宣傳網站模板, 運動跑鞋線上商城網站模板, 全球IT服務公司宣傳網站模板, 現代新能源公司HTML5網站模板, 科技風信息技術服務公司網站模板, 星座占星術資訊分享網站模板, 電臺日程安排網站模板, 卡丁車體驗機構宣傳網站模板, 旅行探險服務機構網站模板, HTML5技術解決服務公司網站模板, 響應式攝影服務機構宣傳網站模板, 數字解決方案服務公司網站模板, IT解決方案HTML5網站模板, HTML5衣物洗護服務網站模板, 響應式工業藝術行業宣傳網站模板, HTML5物流運輸服務機構網站模板, 商業技術投資服務公司網站模板, 響應式電氣服務公司網站模板, HTML5商務諮詢服務公司宣傳網站模板, IT服務技術解決方案公司網站模板, IT支援服務網站HTML5模板, 精英零售商電子商務網站模板, 香水線上購物服務商城網站模板, 電子競技賽服務網站模板, 氣候變化天氣預報服務網站模板, 專業腕錶定製服務網站模板, 醫療保健服務行業宣傳網站模板, 數字營銷代理服務公司網站模板, 旅行移民簽證服務網站模板, 響應式線上娛樂遊戲網站模板, HTML5紫色風格貨幣投資交易網站模板, 香氛蠟燭線上商城網站模板, 人工智慧SEO服務公司網站模板, 計算機資料安全服務公司網站模板, 私人調查服務公司HTML5網站模板, 安家購房房地產宣傳網站模板, 智慧財產權保護辯護服務網站模板, 響應式酒店房間預定服務網站模板, 戶外露營裝備購物服務網站模板, 商業服務IT解決方案HTML5網站模板, 時尚創意設計網路服務公司網站模板, HTML5電子郵件營銷服務公司網站模板, 建築商建築服務公司宣傳網站模板, 兒童慈善機構宣傳網站HTML5模板, 現代營銷服務公司宣傳網站模板, HTML5門窗定製設計服務公司網站模板, 極簡風格數字營銷公司網站HTML5模板, 廢物管理污染解決服務公司網站模板, 酒店體系結構建築設計服務公司網站模板, 數字網路服務公司宣傳網站模板, 現代設計服務機構宣傳網站模板, 現代營銷開發服務公司網站模板, 羽毛球培訓服務機構網站模板, 現代電子商務購買服務平臺網站模板, IT解決方案服務機構宣傳網站模板, 非盈利服務機構宣傳網站模板, 魚類養殖技術服務公司網站模板, HTML5園林設計景觀美化網站模板, 咖啡商店響應式網站模板, 人工智慧線上影象產生網站模板, 游泳池供應商服務宣傳網站模板, 旅行冒險運動定製服務網站模板, HTML5運動健身機構宣傳網站模板, NFT數字藝術作品營銷服務公司網站模板, 現代網際網路服務公司HTML5模板, HTML5高爾夫運動網站模板, 奢侈品手錶服務公司網站模板, 建築專案服務設計公司網站模板, 攝影專業機構作品宣傳網站模板, 一體化網路醫療服務公司網模板, 商業諮詢規劃分析服務公司網站模板, 現代SEO營銷機構宣傳網站模板, 餐飲機器裝置服務公司網站模板, 地板安裝服務公司宣傳網站模板, 響應式航班旅行航空公司網站模板, 志願者服務網站HTML5模板, HTML5專業游泳學校宣傳網站模板, 潛水體驗服務俱樂部網站模板, 漢堡美食餐飲服務網站模板, 馬戲團表演服務機構網站模板, 紫色風格網路安全服務公司網站模板, 響應式現代婚戀網站模板, 網際網路軟體服務公司HTML5模板, 一站式旅行冒險服務機構網站模板, 人工智慧服務響應式網站模板, 最新時事部落格資訊服務網站模板, HTML5數字工作室宣傳網頁模板, HTML5房地產創意服務顧問網站模板, 自行車運動俱樂部服務機構網站模板, 業務推廣宣傳服務公司網站模板, 酒店預訂服務平臺宣傳網站HTML5模板, 響應式廣告發布平臺宣傳網站模板, HTML5舞蹈培訓機構網站模板, 藍色風格虛擬主機服務公司網站模板, 人工智慧服務平臺網站模板, 現代網際網路業務服務公司網站模板, 家庭生活職業輔導機構網站HTML5模板, 綠色園林景觀設計公司網站模板, HTML5工程建築工業服務公司網站模板, 家禽養殖場響應式宣傳網站模板, 兒童教育服務機構HTML5網站模板, 響應式知識付費軟件平臺網站模板, 網站託管服務公司響應式網站模板, 高爾夫俱樂部宣傳網站模板, 網頁設計開發公司作品展示網頁模板, 汽車故障維修保養服務網站模板, HTML5理財規劃融資投資機構網站模板, 響應式運動健身定製服務網站模板, 網站建設服務公司HTML5模板, 響應式室內設計行業宣傳網站模板, 響應式HTML5餐飲店宣傳網站模板, HTML5會計服務公司宣傳網站模板, 咖啡屋咖啡飲品宣傳網站模板, 電子郵件營銷工具服務網站模板, 管道工程服務公司網站HTML5模板, 財務審計管理服務公司網站模板, 響應式園藝景觀設計網站模板, HTML5航空公司宣傳網站模板, 人工智慧數字化服務公司網站模板, 卡通扁平風格太陽能資源網站模板, 網頁開發設計服務公司網站模板, 物流運輸服務管理公司宣傳網站模板, 時尚奢侈品腕錶宣傳網站模板, 國外城市宣傳網站響應式模板, IT軟體設計服務公司網站模板, HTML5高爾夫俱樂部宣傳網站模板, HTML5保險服務公司宣傳網站模板, 響應式房地產公司宣傳網站HTML5模板, HTML5線上職位招聘服務網站模板, 數字IT解決方案服務商網站模板, 響應式旅遊博主個人網頁模板
2020-12-12
745
學習了幾天的 Python 入門,從完全不懂的零基礎開始,直到能完成一個簡單的功能,其實 Python 比其他語言更容易學,程式碼的確很簡潔易記,底下是一個簡單的 Python 網路爬蟲原始碼,執行時會先要求輸入一個正確的網址,然後模擬瀏覽器訪問,自動抓取該網址的原始碼,並存入以該網域加上目前日期時間為檔名的文字檔。
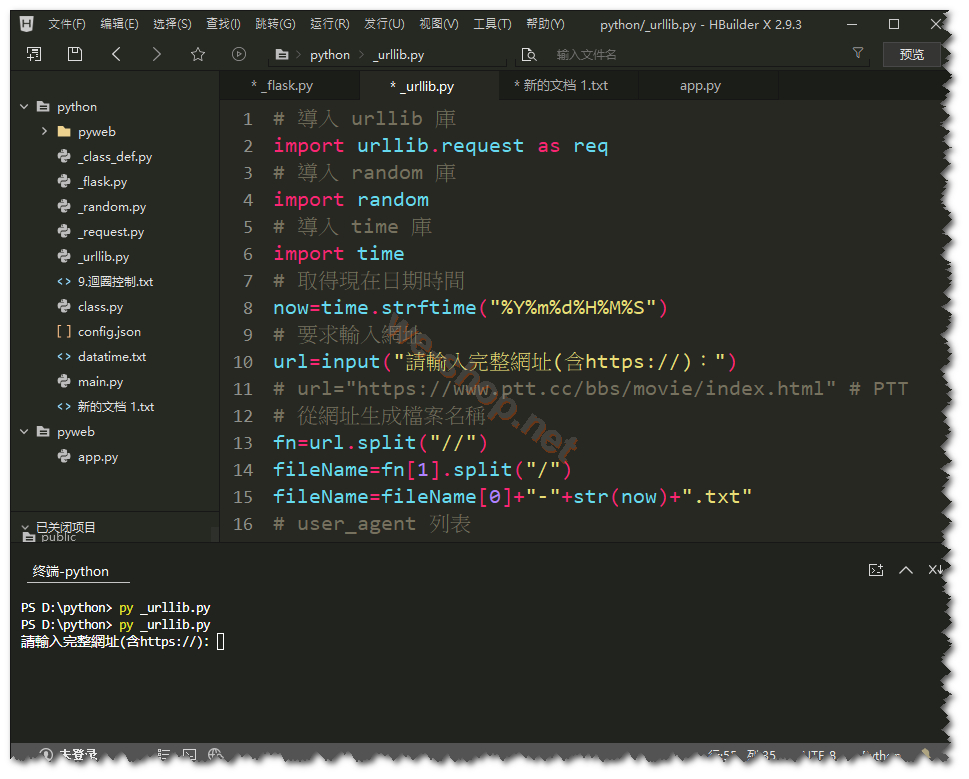
# 導入 urllib 庫
import urllib.request as req
# 導入 random 庫
import random
# 導入 time 庫
import time
# 取得現在日期時間
now=time.strftime("%Y%m%d%H%M%S")
# 要求輸入網址
url=input("請輸入完整網址(含https://):")
# 從網址生成檔案名稱
fn=url.split("//")
fileName=fn[1].split("/")
fileName=fileName[0]+"-"+str(now)+".txt"
# user_agent 列表
user_agent_list = ['Mozilla/5.0 (Windows NT 6.2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1464.0 Safari/537.36','Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.16 Safari/537.36','Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.3319.102 Safari/537.36','Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36','Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36','Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1667.0 Safari/537.36','Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:17.0) Gecko/20100101 Firefox/17.0.6','Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1468.0 Safari/537.36','Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36','Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36']
# 隨機選取一組 user_agent
UA=random.choice(user_agent_list)
# 建立Request物件,附加Headers資訊,偽裝成使用者
request=req.Request(url, headers={
"User-Agent":UA
# "User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Mobile Safari/537.36" # PTT
})
# 打開 url
with req.urlopen(request) as response:
# 將網頁原始碼存到變數data
data=response.read().decode("utf-8")
# print(data)
# 將網頁原始碼變數data寫入文字檔
with open(fileName, mode="w", encoding="utf-8") as file:
file.write(data)
如果還要對抓取的原始碼進行處理,則需要安裝 beautifulsoup 套件pip install beautifulsoup4,beautifulsoup 套件的用法:
# 載入bs4套件解析HTML程式碼
import bs4
# 將整個HTML網頁解析後賦給root
root=bs4.BeautifulSoup(data, "html.parser")
# 取得網頁標題
print(root.title.string)
# 尋找第一個class="title"的DIV
titles=root.find("div", class_="title")
# 所有的超連結
a_tags = root.find_all('a')
for tag in a_tags:
print(tag.string)# 輸出超連結的文字
print(tag.get('href'))# 取出節點屬性
# 同時搜尋多種標籤,搜尋所有超連結與粗體字
tags = root.find_all(["a", "b"])
# 限制搜尋結果數量
tags = root.find_all(["a", "b"], limit=2)
# 尋找所有class="title"的DIV
titles=root.find_all("div", class_="title")
for title in titles:
if title.a != None: # 如果是連結則輸出
print(title.a) # 只輸出標題文字
# print(title.a.string) # 只輸出標題文字
相關文章
9.Python 的迴圈控制 while、for
2020-12-09
8.Python 的條件判斷 if
2020-12-09
7.Python 函數的基本使用
2020-12-08
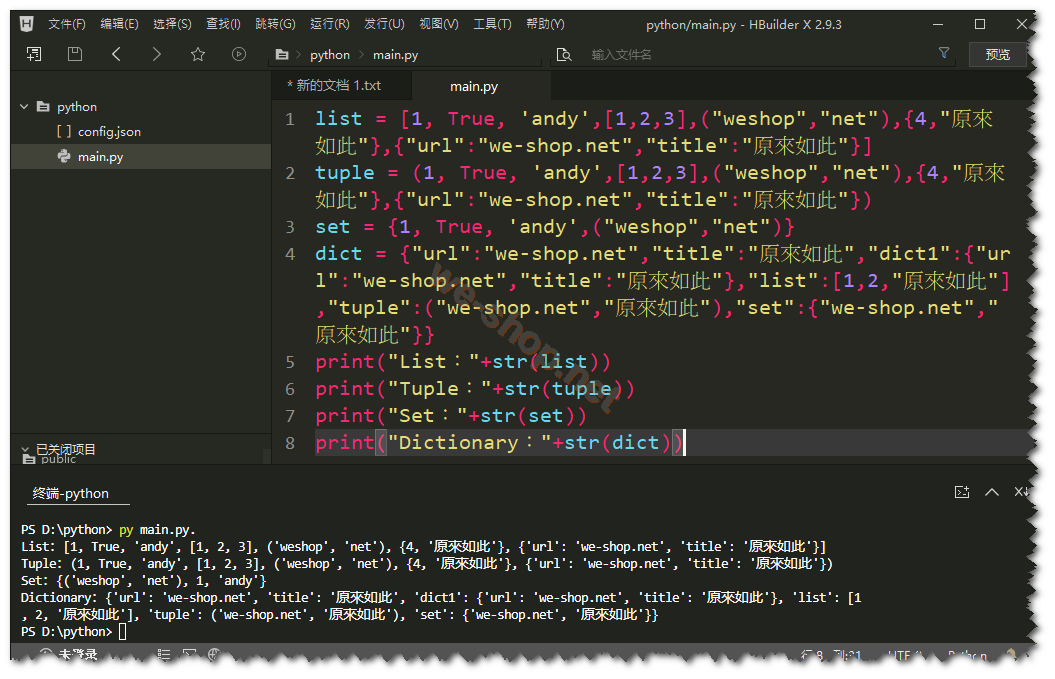
6.Python 列表(List)、元祖(Tuple)、集合(Set)、字典(Dictionary)
2020-12-08
5.Python 數字、字串的定義、運算與格式化
2020-12-06
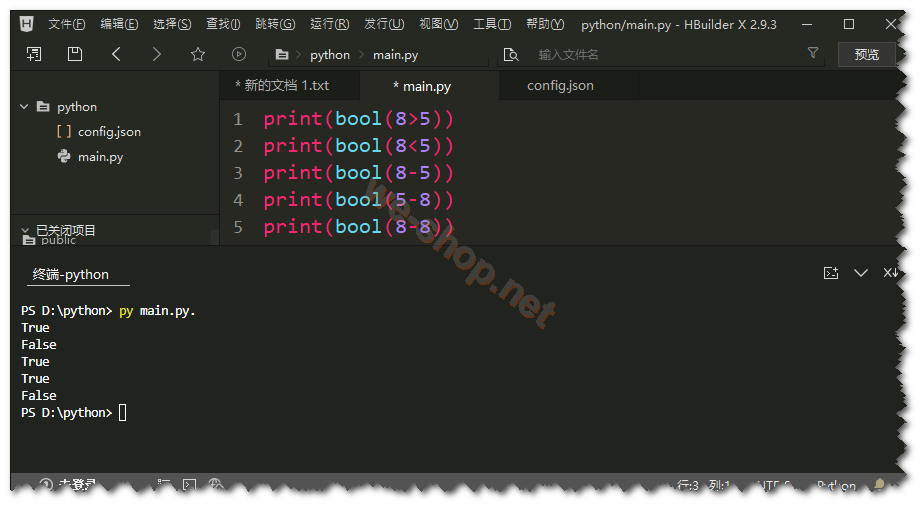
4.Python 數據類型
2020-12-05

3.Python 註解、變數與保留字
2020-12-05

2.Python 如何使用 Hbuilder 編輯器作為開發環境
2020-12-04
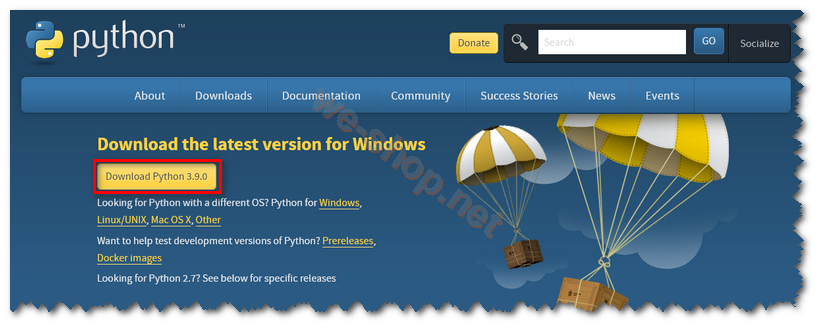
1.Python 下載與安裝
2020-12-03
如果你對10.Python 網路爬蟲原始碼有任何問題請到討論區發帖。